Object Detection with PCA and Synthetic Data
Recently I’ve been playing around with the DINOv2 image feature extraction model. The main thing that piqued my interest about this model is just how general the features are. This makes a lot of sense based on how it’s trained with an unsupervised task.
One of the neat examples shown was foreground object detection via PCA. If you threshold negative values in the first primary component, you end up with a mask of the foreground (generally). If you do a second PCA with these remaining tokens across several images of the same class, you’ll see related object regions with similar component values. Neat stuff!
In practice I found this to not work very reliably with complex images, especially with multiple different objects in the scene. I wanted to see if I could improve this.
First up I needed some sample input data. Since we’re playing with AI, we don’t need a real photo. We can use SDXL to just generate samples for us.
I want to look for dogs in pictures, so let’s write code to generate that.
All code for this project can be found here.
from diffusers import StableDiffusionXLPipeline
import torch
img_size=1024
sdxl_model_id = "stabilityai/stable-diffusion-xl-base-1.0"
pipe = StableDiffusionXLPipeline.from_pretrained(sdxl_model_id, torch_dtype=torch.float16, variant="fp16").to("cuda")
input_image = pipe(
prompt="A photo of a dog playing with a soccer ball in a park",
guidance_scale=8.0,
num_inference_steps=100,
).images[0]
Here we simply load an SDXL pipeline through the huggingface diffusers library.
When we run the code above with the prompt "A photo of a dog playing with a soccer ball in a park" we get something that looks like the following picture.

Next we need some example data of dogs. We’re going to perform PCA on these “guidance” images to filter out the “dog tokens”. These will help us with classification later. Since this process is a bit flimsy, we can use synthetically generated data framed in such a way to be optimal for this process. In our case we can just use SDXL again. We only need a few guidance samples, but more quantity and diversity should be even better if you have the cycles.
num_guides = 5
guide_images = pipe(
prompt=["A high quality photo of a fullbody dog"] * num_guides,
guidance_scale=8.0,
num_inference_steps=50,
).images
With this prompt we get images like this:

When testing this with limited samples, adding fullbody into the prompt really helped. Gotta make sure all the relevant features are there!
Now that we have our input image and guidance images, we can use DINOv2 to extract their patch features. DINOv2 patch features correspond to a 14x14 region in the input. These features are returned as a flattened tensor, and also have one additional vector for the CLS token. We’re primarily focused on the patch features, so we can ditch the CLS token.
from transformers import AutoImageProcessor, Dinov2Model
dino_model_id = "facebook/dinov2-base"
image_processor = AutoImageProcessor.from_pretrained(dino_model_id, do_center_crop=False, do_resize=False)
model = Dinov2Model.from_pretrained(dino_model_id, device_map="cuda:0")
inputs = image_processor(images=[input_image] + guide_images, return_tensors="pt").to("cuda:0")
with torch.inference_mode():
outputs = model(**inputs)
patch_features = outputs.last_hidden_state[:, 1:, :] # remove the CLS token
As I mentioned, these patch features are flat right now. Later we’ll want to unflatten them so we can display them as pictures, so we can make a little helper function. Remember these are 14x14 patches, so it’s smaller than the original image.
def unflatten_features(features, batch_size=1, patch_size=14):
return features.reshape(batch_size, img_size // patch_size, img_size // patch_size, -1)
Now we get to the magical world of principal component analysis. The authors of the DINOv2 paper showed that PCA on patch features has the effect of discriminating between the foreground and background. Subsequent PCA passes using data from multiple images also allows for cross-image correlations to be found.
In the paper they separate the foreground object by thresholding on the first primary component. Basically if this value is negative, remove it from the mask.
We’re going to use PCA a few times, so we’ll write a helper function for that.
def thresholded_pca(x, n_components=3):
# center the data
x_mean = torch.mean(x, dim=0)
x = x - x_mean
# perform SVD and get principal components
_, _, v = torch.svd(x)
components = torch.mm(x, v[:, :n_components])
# mask on positive primary component
mask = components[:, 0] > 0
# normalize
min_val = torch.min(components)
max_val = torch.max(components)
components = (components - min_val) / (max_val - min_val)
# apply threshold mask
components = components * mask[:, None].float()
return components
We can now use this to perform a sort of “dog token” filtering on our guidance examples. We want a long list of “dog tokens” we can use for object detection.
First we perform the thresholded PCA and then effectively use it as a mask on the original patch features. Easy enough.
# extract guide patch features and flatten
guide_patch_features = patch_features[1:]
flat_guide_patch_features = guide_patch_features.reshape(-1, guide_patch_features.shape[-1]).cpu()
# perform PCA and filter for our dog tokens
pca_patch_features = thresholded_pca(flat_guide_patch_features)
guide_patch_features_filtered = flat_guide_patch_features[pca_patch_features[:, 0] > 0]
# unflatten for display
pca_patch_features = unflatten_features(pca_patch_features, batch_size=num_guides)
And when we display them we can see we do in-fact have a decent foreground mask.

With our nice dataset of dog vectors in hand, we can now use them when we perform PCA on new input images. Ideally they should assist in the masking quality for the object of our choice, in this case a dog.
We just have to perform PCA with the new image just like we’ve done before, except this time concatenate the guidance vectors. We trim the output to size afterwards.
In the following code we use PCA on the input alongside various other guidance strategies. First we use the filtered guidance vectors, then unfiltered guidance vectors, and finally no guidance vectors.
# perform combined PCA on input patches and filtered guide patches
input_patch_features = patch_features[0].cpu()
# get patches with filtered example data
pca_patch_features = thresholded_pca(
torch.cat([input_patch_features, guide_patch_features_filtered], axis=0)
)[:input_patch_features.shape[0]]
# get patches with unfiltered example data
pca_unfiltered_guidance = thresholded_pca(
torch.cat([input_patch_features, flat_guide_patch_features], axis=0)
)[:input_patch_features.shape[0]]
# get patches without example data
pca_no_guidance = thresholded_pca(input_patch_features)
feature_maps = [unflatten_features(f).squeeze(0) for f in [pca_patch_features, pca_unfiltered_guidance, pca_no_guidance]]
You can see that having the filtered dataset greatly improves this process.
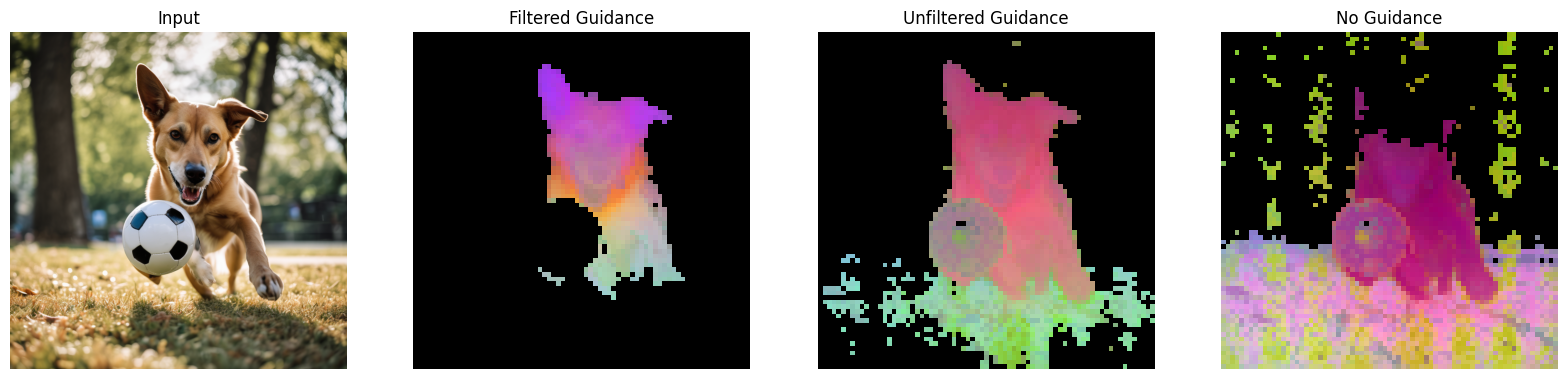
Great! We’ve been able to use synthetic data to guide our PCA. I love how it even masks out the ball in front of the dog.
From here you can do all sorts of things, since we’re fairly effectively performing dense object prediction. For the case of this demo, I think I’d like to do a little object replacement.
First, we need a cleaner mask. It needs to be smoother and higher resolution. There are also some small holes I’d like filled in. We can do a little post processing to clean this up.
import torch.nn.functional as F
# create mask from thresholded PCA components
mask = unflatten_features(pca_patch_features[..., 0]) > 0
mask = mask.permute(0, 3, 1, 2).float()
# dilate the mask to cover more area
mask = F.conv2d(mask, torch.ones(1, 1, 3, 3), padding=1) > 0
# upsample and round to get a smoother and higher resolution mask
mask = F.interpolate(mask.float(), size=(img_size, img_size), mode="bilinear").round()
mask = mask[0, 0]
When we run this, we get a pretty decent mask.

Mask in hand, we can do a little image inpainting now. We can call on our friend SDXL once more for the job.
Dogs playing soccer are cool, but tigers playing it are way cooler.
from diffusers import StableDiffusionXLInpaintPipeline
pipe = StableDiffusionXLInpaintPipeline.from_pretrained(sdxl_model_id, torch_dtype=torch.float16, variant="fp16").to("cuda")
inpaint_image = pipe(
prompt="A photo of a baby tiger playing with a soccer ball in a park",
image=input_image,
mask_image=mask,
guidance_scale=8.0,
num_inference_steps=50,
strength=0.75
).images[0]
Finally, side by side with the original input we get some magic.

This project ended up being a lot of fun to work on, and I’m glad I can share some of my enthusiasm and findings with other people. If you end up playing with this or similar ideas, let me know! I’d love to chat.